JPEG Resize on-demand: FPGA vs GPU. Which is the fastest?
Author: Fyodor Serzhenko
High performance image processing is essential task for web applications. It's not a rare situation when companies need to process hundreds of millions images every day. In some services that number could reach several dozens of billions images per day. Here we review available hardware and software solutions for such tasks. We will not consider CPU-based implementations here and focus on FPGA vs GPU as the fastest hardware for parallel computations.
Internet traffic is increasing by ~25% annually (according to white paper from CISCO, see below) and images take considerable part of that data. Many companies are handling huge volumes of images in their data centers:
- Cloud storage, CDN
- Mobile instant messaging
- Images for social networks, image social platforms, cloud albums, photo hosting centers
- User-Generated Content platforms (UGC)
- E-Commerce platforms
Market demand
- Users generate more images and video data every day
- User devices have higher resolution in capture and display
- Users strive to better viewing experience
- Better image quality and QoS
- Customers demand instant access to the resource (reduced latency)
Challenges
- Huge consumption of computational and storage resources
- Server and storage performance is not enough
As a task for performance and latency comparison for FPGA vs GPU at image processing, we will consider JPEG Resize on-demand which is widely utilized in web applications. Total number of JPEGs in the world is absolutely huge and it's significantly increasing every day. That's why companies spend quite a lot on storages for these pictures and on hardware/software for image processing. The simplest approach is to store the same JPEG picture at several different resolutions and to send an image which is slightly bigger at each request. Such an approach can't match desired image resolution exactly. To cut the expences on storage and to respond to user faster, we can resize JPEG images in realtime according to necessary dimensions to accomplish full match with the requirements of user's device. In that case we need to store at datacenter just one original picture which will be processed according to individual request parameters. That idea about on-demand resize for JPEG images is not new and it has already been implemented in several internet services on CPU, GPU and FPGA.
Image processing pipeline for JPEG Resize on-demand
- JPEG Decoding
- Resizing and Cropping
- Sharpening
- Color profile handling
- JPEG Encoding
That pipeline consists of different algorithms and we could hardly implement batch processing here for the whole pipeline, as soon as final dimensions are different, images could have different subsampling, individual quantization tables and Huffman tables. It means that we have to process these algorithms sequentially, though still there is a possibility to get a boost from batch mode. Most of the time in the pipeline is spent on JPEG Decoding, so we could implement batch just for JPEG decoding. We can prepare images for future batching by utilizing the same subsampling, quantization tables and Huffman tables. File size will increase a little bit, but we will get an opportunity to accelerate JPEG decoding.
Image Processing on FPGA
FPGA (Field Program Gate Array) is a specialized reconfigurable hardware which could be also utilized for fast image and video processing. This is very complicated approach for programming and FPGA engineers should know quite a lot: hardware architecture, Verlog or VHDL language, Intel (Altera) or Xilinx development tools, etc. Total understanding of hardware functioning is a must, so not everyone could do that. Still, that approach is evolving rapidly and there are some outstanding results in that field.
FPGA-based solutions posess some features which could hardly be beaten: hardware-based computations are usually very fast, the hardware could have very low dimensions and it could have extremely low power consumption. These are indispensible conditions for many embedded applications. In comparison with FPGA, any CPU or GPU-based solutions have bigger dimensions and need more power for processing with the same performance.
Despite the fact that FPGA-programming is very complicated, there are quite a lof of imaging solutions which are based on FPGA/ASIC hardware. Moreover, neural networks have already been implemented on FPGA and that hardware platform is considered to be very promising for Deep Learning and Artificial Intelligence tasks. Currently, neural networks are much more easier to implement on GPU, than on FPGA. But FPGA is a competitive solution, though at the moment it requires super high skills to work with.
Some frame grabbers have built-in library for internal FPGA-based image processing. Silicon Software framegrabbers (now belongs to Basler company) have such a feature and this is the way to implement FPGA-based image processing for camera applications without writing any code on VHDL or Verilog. This is important task to ensure faster than realtime image processing on FPGA for high speed and high performance cameras.
 CTAccel solutions on Intel FPGAs CTAccel solutions on Intel FPGAs
CTAccel company is based in Hong Kong and Shenzhen. This is a team of FPGA professionals with solid record of achievments in FPGA design, hardware/software co-design, system optimization and software engineering. The core team of CTAccel comes from the FPGA team of Clustertech Ltd.
CTAccel Image Processing Solutions
CTAccel Image Processor (CIP) effectively accelerates the following image processing/analytics workflows:
- Thumbnail Generation/Transcoding
- Image processing (sharpen/color filter)
- Image analytics
CIP includes the following FPGA-based accelerated functions:
- Decoder: JPEG
- Pixel processing: Resize/Crop
- Encoder: JPEG, WebP, Lepton
- Software compatibility with OpenCV, ImageMagick and Lepton
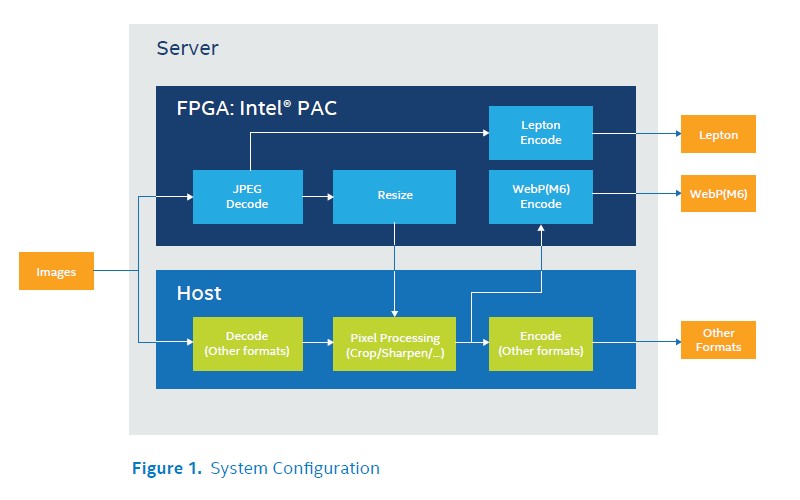
CIP Image Processing Pipeline (image from that PDF)
That diagram for suggested image processing pipeline shows that Crop, Sharp and Color conversions are implemented on Host CPU, not on FPGA. In that case we get combined heterogeneous solution, where image processing is done both on FPGA and CPU. This leads to additional load for CPU.
Intel FPGA board (image from that PDF)
The CIP accelerator features an Intel® Programmable Acceleration Card (PAC) with Intel Arria® 10 GX FPGA.
Performance evaluation for CTAccel CIP solution on Intel PAC
JPEG Resize solution from CTAccel for Intel® Programmable Acceleration Card can do JPEG decoding, image resize and JPEG encoding. This is the screenshot for Real-world customer use case from CTAccel site:
8 MPix image is converted to thumbnail on Intel Xeon E5-2639 v2 CPU within 10 ms (100 sec / 10,000 images), which means that on CTAccel CIP that image could be processed within 2 ms (total computation time 10 ms reduced by 80%). For further comparison we can conclude that 3 MPix jpeg image could be resized on Intel PAC with CTAccel CIP within 0.8 ms which is equal to 1250 fps (frames per second).
Averaged latency for 3 MPix image processing on FPGA is the following: (240 ms * (100 - 80) / 100 * 3 / 8 = 18 ms. This actually means that FPGA is processing around 18 / 0.8 = 22 images at the same time. It looks like a batch mode for JPEG decoding on CIP has already been implemented.
Unfortunately we don't have full info about parameters for that pipeline. Nevertheless, we can expect that original compressed image should be close to visually lossless compression. "Generating thumbnails" approach means that final image resolution is very small, so applied resize takes less time and output JPEG encoding takes almost no time. In real-life case of JPEG Resize on-demand we need to fit resolution of smartphone screen, and this is more computationally intensive (that scenario was used for tests with NVIDIA Tesla T4 GPU). Still, these performance results could be a ground to make indirect comparison with benchmarks on NVIDIA Tesla T4. To the best of our knowledge, pricing for Intel PAC board and NVIDIA T4 is comparable.
XILINX
Xilinx Alveo, a portfolio of powerful accelerator cards designed to dramatically increase performance in various tasks. Xilinx® Alveo™ U280 Data Center accelerator cards are designed to meet the constantly changing needs of the modern Data Center. Built on the Xilinx 16nm UltraScale™ architecture, Alveo U280 ES offers 8 GB of HBM2 410 GB/s bandwidth to provide high-performance, adaptable acceleration for memory-bound, compute intensive applications including database, analytics, and machine learning inference. The U280 ES acceleration card includes PCI Express 4.0 support to leverage the latest server interconnect infrastructure for high-bandwidth host processors. And like all Xilinx technology, customers can reconfigure the hardware, enabling them to optimize for shifting workloads, new standards and updated algorithms without incurring replacement costs.
Alveo accelerator cards are adaptable to changing acceleration requirements and algorithm standards, capable of accelerating any workload without changing hardware, and reduce overall cost of ownership.
Xilinx Alveo U280 Data Center accelerator card (image is taken here)
There are some libraries which allow to implement image processing algorithms on FPGA via C++ instead of Verilog/VHDL, though finally VHDL code will be generated. Xilinx Video and Image Processing Pack is an example how to do that. It includes full licenses to the following LogiCORE IP cores:
- Chroma Resampler
- Color Correction
- Color Filter Array Interpolation
- Gamma Correction
- Image Edge Enhancement and Image Noise Reduction
- On-Screen Display
- Video Deinterlacer
- Video DMA
- Video Timing Controller
The Xilinx Video and Image Processing Pack provides bundled licensing option for all of the LogiCORE™ IP blocks. Video processing blocks provide optimized hardware implementations for video scaling, on-screen display, picture-in-picture, text overlay, video and image analysis and more. Image processing blocks enable pre-processing of images captured by a color image sensor with a Bayer Color Filter Array (CFA), correcting defective pixels, interpolating missing color components for every pixel, correcting colors to adjust to lighting conditions, setting gamma to compensate for the intensity distortion of different display devices and more.
CTAccel on Virtex UltraScale+ VCU1525
The above set of image processing features from Xilinx LogiCORE IP cores is not enough to accomplish the task of JPEG Resize on-demand. That task was solved on Xilinx FPGA hardware by CTAccel company, as in the case with Intel FPGA. That solution from CTAccel on Xilinx is utilized by Huawei Cloud for FPGA Image Transcoding Acceleration on Virtex VU9P to provide easy-to-use and cost-effective image transcoding services. For the task of thumbnail generation (which is alike the task of JPEG Resize on-demand, but more simple), published benchmarks for performance and latency are the same as for Intel FPGA solution - this is 0.8 ms for 3 MPix jpeg image. It should be noted that the same CTAccel CIP solution can work on Xilinx Alveo accelerator cards as well.
Xilinx VCU1525 developer board (image is taken here)
GPU Image Processing on NVIDIA CUDA
GPU architecture was initially created for image display and finally it was transformed for parallel computations. Image processing could be considered as native task for GPU, though we need SDK not to program GPU at low level. There are quite a lot of such SDKs with sofisticated set of features.
Full set of features for JPEG resize on demand exists at Fastvideo Image Processing SDK. That SDK contains wide variety of image processing modules which show very high performance at all NVIDIA GPUs, starting from Jetson to high-end Quadro and Tesla products. Highly optimized modules show just exceptional results. For many features the performance is much higher that bandwidth of PCIe Gen3 x16. This is important issue to offer fast solution, particularly for JPEG resize on demand.
That solution has been heavily tested for years and this is the proof of its reliability in the taks of JPEG Resize on-demand. Several high-load internet services have been utilizing that software and total number of processed JPEGs exceeds several quadrillions. In comparison with recently developed FPGA-based solutions it looks much more reliable.
Fastvideo Image Processing SDK on NVIDIA T4 can do decode-resize-sharp-encode at 1.2 ms for 3 MPix image resize which is around 800 fps, but this is the result without batch mode. As soon as image resize on GPU takes small part of that time, we see that performance on JPEG Decoder is the key to achieve maximum speed for that task. Usually resized image has smaller resolution and output JPEG Encoder can process it very fast. In general, GPU JPEG Encoder is much faster than GPU JPEG Decoder, that's why JPEG decoding is the bottleneck for that task.

Despite the fact that we haven't yet implemented our own batch mode for JPEG Resize on-demand, there is an opportunity to increase GPU occupancy with CUDA MPS on Linux. CUDA MPS allows to utilize NVIDIA Hyper-Q technology in multi-process environment and this is the way to get much better performance if GPU is underutilized (this is exactly our case). We have run 4 processes of JPEG Resize on-demand on NVIDIA T4 and have achieved significant speedup with CUDA MPS. We've got final performance 2200 fps with CUDA MPS on NVIDIA Tesla T4.
The feature of FPGA partial reconfiguration doesn't bring any additional benefits in comparison with GPU solutions for high performance image processing tasks. Basically, the performance is defined by the hardware and software. And if we need to run any other task on the same hardware, we just need to load another software from available image processing modules. In the case with GPU, this is actually a question about availability of necessary modules in the software. Fastvideo Image Processing SDK has great variety of such modules and it can also work with any other third-party SDK, so the choice of available software features for CUDA image processing on Tesla T4 is impressive.
It should be noted that currently, versatility of GPU is much more profound in comparison with FPGA. NVIDIA GPUs have a lot of libraries which help developers to build their applications. And the idea of utilizing COTS (Commercial Off-The-Shelf) is very handy. GPU and FPGA have totally different architectures and that's why their "killer applications" are also quite different. NVIDIA, Intel and Xilinx invest a lot into their software, hardware, infrastructure, community and try to promote their solutions at full extent. They do compete everywhere and NVIDIA is now succeeding with implementation of embedded solutions on Jetson platform, though embedded solutions were always the main market niche for FPGA/ASIC. Intel and Xilinx are moving towards DL/AI to compete with NVIDIA as well.
Conclusions
We have published available results for GPU vs FPGA performance and latency for JPEG Resize on-demand task. That comparison is indirect because we have benchmarks for different scenarios: for FPGA this is thumbnail generation case for JPEG images, for GPU this is standard JPEG resize to most frequently used resolution which was acquired from statistics.
- Achieved performance for the above tasks look very good in both cases: NVIDIA Tesla T4 result is around 2200 fps for JPEG Resize with CUDA MPS. Intel/Xilinx result is around 1250 fps for thumbnail generation with internal batch decoding, which is more simple task because it requires less computations. We can see that NVIDIA Tesla T4 significantly outperforms Intel/Xilins FPGA boards and we need to bear in mind that FPGA benchmarks were received in simplified test.
- Computational latency in these tasks for NVIDIA Tesla T4 is 2-3 ms, for FPGA this is 18 ms.
- FPGA dimensions and power consumption are not vitally important for JPEG Resize on-demand task. FPGA boards look like GPU boards and their dimensions are the same, though power consumption is still less for FPGA-based solutions which have 20W - 40W per FPGA card and 70W for NVIDIA Tesla T4.
- Ease of programming is also looks alike, because mostly developers are utilizing high-level SDKs. If we have a look at low-level programming, then FPGA is much more complicated to handle.
- Partial Reconfiguration and flexibility are essential benefits of FPGA, but for the current task they are not really important.
- Reliability of GPU-based solution is higher due to long-term presence on the market.
- Both GPU and FPGA could be utilized for other tasks, including DL/AI applications.
- GPU-based solutions are basically software implementations, though FPGA solutions imply that there is non-standard hardware to work with. This is a great advantage of NVIDIA GPUs - they are commodity things. At the moment we can't call FPGA-based boards from Intel and Xilinx as commodity things yet.
- NVIDIA, Intel (Altera), Xilinx, CTAccel, Fastvideo are great companies which move progress forward and create impressive software and hardware solutions for high performance applications.
What we finally get
GPU and FPGA high-performance processing capabilities offers the following benefits:
- Increased image processing throughput
- Reduced TCO
- Reduced computational latency
- Reduced size of cluster or less total number of servers
- Low CPU utilization
- Better user experience and QoS:
- Less time to wait for image loading
- Less power consumption on users's device
- Less traffic due to optimal image resolutions
- Better image quality (no local image resize on user's device)
Links
|