
Jpeg2Jpeg Acceleration with CUDA MPS on LinuxThe task of fast JPEG-to-JPEG Resize is essential for high load web services. Users create most of their images with smart phones and cameras in JPEG format which is the most popular nowadays. To offer high quality services and to cut expences on storages, providers strive to implement JPEG resize on-the-fly to store just one image instead of several dozens in different resolutions. Solutions for fast JPEG resize, which are also called Jpeg2Jpeg, have been implemented on CPU, GPU, FPGA and on mobile platforms as well. The highest performance for that task was demonstrated on GPU and FPGA, which used to be considered on par for NVIDIA Tesla T4 and Xilinx VCU1525 or Alveo U280 hardware.

Bottlenecks for high performance Jpeg2Jpeg solutions on GPUImplementation of fast JPEG Resize (Jpeg2Jpeg transform) is quite complicated task and it's not easy to boost highly optimized solution. Nevertheless, we can point out some issues which still could be improved:
In general, GPU can offer super high performance only in the case if there is sufficient amount of data for parallel processing. If we don't have enough data, then GPU occupancy is low and we are far from maximum performance. We have exactly the same issue with the task of JPEG Resize on GPU: usually we have non-sufficient amount of data and GPU occupancy is not high. One way to solve that matter is to implement batch mode. Batch mode implies that the same algorithm could be applied at the same time to many items which we need to process. This is not exactly the case with JPEG Resize, because it should be possible to implement batch processing for JPEG decoding, though Resize is difficult to include at the same batch as soon as for each image we need to generate and to utilize individual sets of interpolation coefficients. And scaling ratio is usually not the same for all processed images in the batch. That's why batch mode could be limited by JPEG decoding only. If we have a look at existing FPGA-based solutions for Jpeg2Jpeg software, all of them are utilizing batch JPEG decoding and then individual resize and encoding to get better performance. Optimization of JPEG decoder could be done by taking into account the latest NVIDIA architecture to boost the performance of entropy decoder, which is the most time-consuming part of JPEG algorithm. Apart from entropy decoder optimization, it makes sense to accelerate all other parts or JPEG algorithm. Finally, we've found the way how to accelerate the current version of JPEG Resize on GPU from Fastvideo Image Processing SDK and this is the answer: NVIDIA CUDA MPS. Below we condiser in detail what's CUDA MPS and how we could utilize it for that task. CUDA Multi-Process ServiceThe Multi-Process Service (MPS) is an alternative, binary-compatible implementation of the CUDA Application Programming Interface (CUDA API). The MPS runtime architecture is designed to transparently enable co-operative multi-process CUDA applications, typically MPI jobs, to utilize Hyper-Q capabilities on the latest NVIDIA (Kepler-based) GPUs. Hyper-Q allows CUDA kernels to be processed concurrently on the same GPU. This can benefit performance when the GPU compute capacity is underutilized by a single application process. MPS is a binary-compatible client-server runtime implementation of the CUDA API, which consists of several components:
To balance workloads between CPU and GPU tasks, MPI processes are often allocated individual CPU cores in a multi-core CPU machine to provide CPU-core parallelization of potential Amdahl bottlenecks. As a result, the amount of work each individual MPI process is assigned may underutilize the GPU when the MPI process is accelerated using CUDA kernels. While each MPI process may end up running faster, the GPU is being used inefficiently. The Multi-Process Service takes advantage of the inter-MPI rank parallelism, increasing the overall GPU utilization. NVIDIA Volta architecture has introduced new MPS capabilities. Compared to MPS on pre-Volta GPUs, Volta MPS provides a few key improvements:
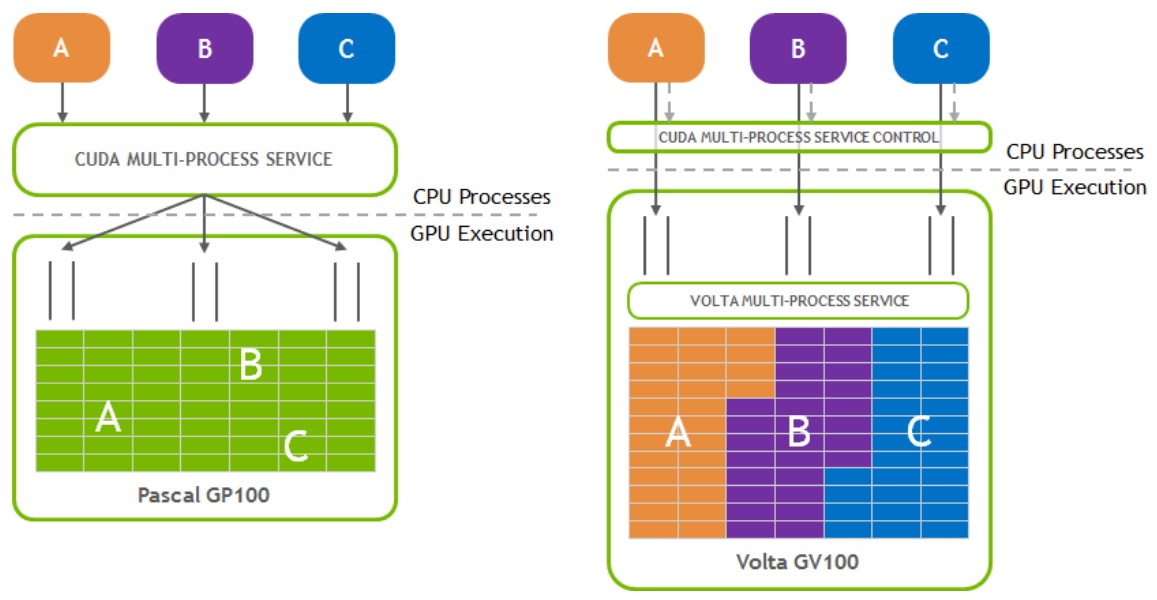
Fig.1. Pascal and Volta MPS architectures (picture from NVIDIA MPS Documentation) CUDA MPS Benefits
CUDA MPS Limitations
GPU Compute ModesThree Compute Modes are supported via settings accessible in nvidia-smi.
Using MPS effectively causes EXCLUSIVE_PROCESS mode to behave like DEFAULT mode for all MPS clients. MPS will always allow multiple clients to use the GPU via the MPS server. When using MPS, it is recommended to use EXCLUSIVE_PROCESS mode to ensure that only a single MPS server is using the GPU, which provides additional insurance that the MPS server is the single point of arbitration between all CUDA processes for that GPU. Client-Server ArchitectureThis diagram shows a likely schedule of CUDA kernels when running an MPI application consisting of multiple OS processes without MPS. Note that while the CUDA kernels from within each MPI process may be scheduled concurrently, each MPI process is assigned a serially scheduled time-slice on the whole GPU.
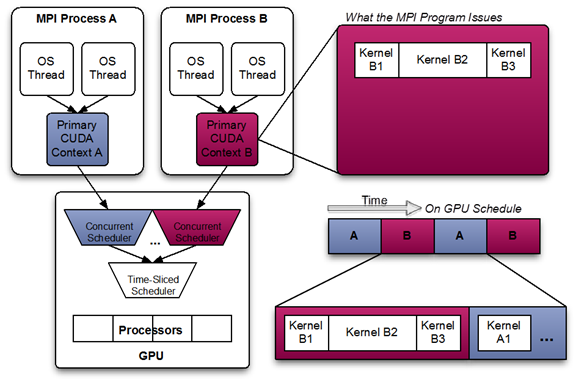
Fig.2. Multi-Process Sharing GPU without MPS (picture from NVIDIA MPS Documentation)
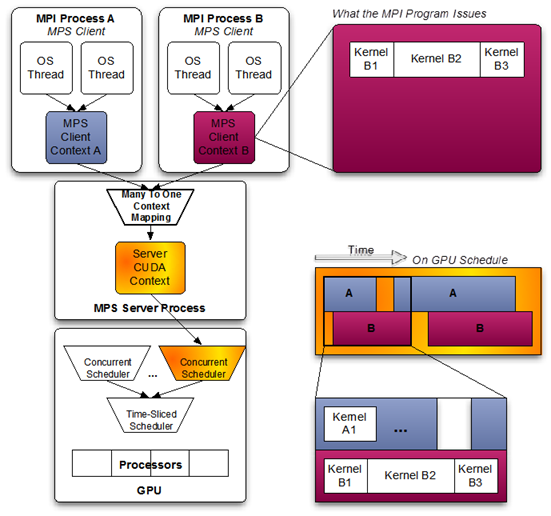
Fig.3. Multi-Process Sharing GPU with MPS (picture from NVIDIA MPS Documentation)
When using pre-Volta MPS, the server manages the hardware resources associated with a single CUDA context. The CUDA contexts belonging to MPS clients funnel their work through the MPS server. This allows the client CUDA contexts to bypass the hardware limitations associated with time sliced scheduling, and permit their CUDA kernels execute simultaneously. Volta provides new hardware capabilities to reduce the types of hardware resources the MPS server must managed. A client CUDA context manages most of the hardware resources on Volta, and submits work to the hardware directly. The Volta MPS server mediates the remaining shared resources required to ensure simultaneous scheduling of work submitted by individual clients, and stays out of the critical execution path. The communication between the MPS client and the MPS server is entirely encapsulated within the CUDA driver behind the CUDA API. As a result, MPS is transparent to the MPI program. MPS clients CUDA contexts retain their upcall handler thread and any asynchronous executor threads. The MPS server creates an additional upcall handler thread and creates a worker thread for each client. ServerThe MPS control daemon is responsible for the startup and shutdown of MPS servers. The control daemon allows at most one MPS server to be active at a time. When an MPS client connects to the control daemon, the daemon launches an MPS server if there is no server active. The MPS server is launched with the same user id as that of the MPS client. If there is an MPS server already active and the user id of the server and client match, then the control daemon allows the client to proceed to connect to the server. If there is an MPS server already active, but the server and client were launched with different user id’s, the control daemon requests the existing server to shutdown once all its clients have disconnected. Once the existing server has shutdown, the control daemon launches a new server with the same user id as that of the new user's client process. The MPS control daemon does not shutdown the active server if there are no pending client requests. This means that the active MPS server process will persist even if all active clients exit. The active server is shutdown when either a new MPS client, launched with a different user id than the active MPS server, connects to the control daemon or when the work launched by the clients has caused an exception. The control daemon executable also supports an interactive mode where a user with sufficient permissions can issue commands, for example to see the current list of servers and clients or startup and shutdown servers manually. Client Attach/DetachWhen CUDA is first initialized in a program, the CUDA driver attempts to connect to the MPS control daemon. If the connection attempt fails, the program continues to run as it normally would without MPS. If however, the connection attempt succeeds, the MPS control daemon proceeds to ensure that an MPS server, launched with same user id as that of the connecting client, is active before returning to the client. The MPS client then proceeds to connect to the server. All communication between the MPS client, the MPS control daemon, and the MPS server is done using named pipes and UNIX domain sockets. The MPS server launches a worker thread to receive commands from the client. Upon client process exit, the server destroys any resources not explicitly freed by the client process and terminates the worker thread. Important Application Considerations
Performance measurements for Jpeg2Jpeg applicationFor software testing we've utilized the following scenarious:
Hardware and software
These are main components of Jpeg2Jpeg software
If we are working with CUDA MPS activated, then the total number of processes in Jpeg2jpeg software is limited by the amount of available CPU cores. To check CUDA MPS mode, we executed the following commands
Then we started 2/4/6 daemons of JPEG Resize application on NVIDIA Quadro GV100 GPU. We've also done the same without CUDA MPS to make a comparison. How we measured the performanceTo get reliable results which have good correspondence with JPEG Resize algorithm parameters, for each test we've utilized the same image and the same parameters for resizing and encoding. We've repeated each series 1,000 times and calculated average FPS (number of frames per second) for processing. Speedup is calculated as the current value of "FPS with MPS" divided to the best value from "FPS without MPS" column. Jpeg2Jpeg performance with and without MPS for 1K JPEG Resize from 1280×720 to 320×180
Jpeg2jpeg performance with and without MPS for 2K JPEG Resize from 1920×1080 to 480×270
We see that performance saturation in that task could probably be connected with the number of utilized CPU cores. We will check the performance on multicore Intel Xeon CPU to find the solution with the best balance between CPU and GPU to achieve maximum acceleration for Jpeg2Jpeg application. This is essentially heterogeneous task and all hardware components should be carefully chosen and thoroughly tested. Jpeg 2 Jpeg acceleration benchmarks for CUDA MPS on LinuxWe've been able to boost the Jpeg2Jpeg software with CUDA MPS on Linux significantly. According to our time measurements, total performance for JPEG Resize application at CUDA MPS mode was increased by 2.8–3.4 times, which is difficult to believe. We have been able to accelerate the solution that was already well-optimized and it was one of the fastest on the market. For standard use cases on NVIDIA Quadro GV100 we've got benchmarks around 760–830 fps (images per second) and with CUDA MPS at the same test conditions and at the same hardware we've reached 2140–2870 fps. Such an impressive performance boost is absolutely astonishing and we've checked that many times. It's working well and very fast. Moreover, we have fair chances to get even better acceleration by utilizing more powerful multicore CPU. GPU and FPGA solutions for Jpeg2Jpeg applications were on par recently, but this is not the case anymore. Now NVIDIA GPU with Jpeg2Jpeg software from Fastvideo have left behind both CPU and FPGA solutions. There is a use case where Jpeg2Jpeg transform on GPU could be much more efficient in comparison with CPU and FPGA solutions which are quite good if we need to create thumbnails from JPEG images. If we need to implement JPEG resize where image width and height should be changed to a small extent, then Jpeg2Jpeg perfromance on GPU will be much better then on CPU/FPGA. References
|